血液中重复DNA的数量提示早期癌症
癌症患者与未患癌症的人相比,具有不同数量的重复 DNA(称为 Alu 元素)。现在,机器学习可以通过抽血来测量这一点。约翰·霍普金斯金梅尔癌症中心的研究人员利用这一发现改进了一种早期检测癌症的测试,通过从比此类研究典型的十倍大的样本量开始验证和重现结果。
该研究发表于 1 月 24 日《科学转化医学》杂志上。
Alu 元件很小:DNA 梯子的 20 亿步长中约有 300 个碱基对。但是,该研究的主要作者Christopher Douville 博士解释说,无论癌症起源于何处,人们血浆中 Alu 元素的比例都会发生变化。约翰·霍普金斯大学肿瘤学助理教授。
“血液检测对于在人们表现出任何症状之前及早发现癌症具有很大的希望,”杜维尔说。“然而,当微小的波动在这些复杂的模型中产生截然不同的预测时,用机器学习分析结果“并不一定能为患者带来长期的成功。为了对患者护理产生长期影响,医生和患者必须相信模型能够一致且可重复地对癌症状态进行分类。在我们的手稿中,我们多次评估了 1,686 个人,以评估我们的机器学习模型是否始终提供相同的答案。”
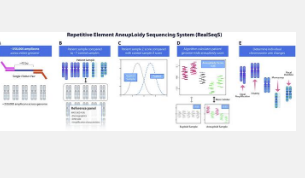
Douville 和同事开发了一种测试来检测癌症中发现的非整倍性、染色体拷贝数改变。该测试通过一种称为液体活检的血液测试来测量非整倍性,该测试可检测血液中循环的癌细胞 DNA 片段。
然而,杜维尔观察到一种无法解释的信号,可以区分癌症和非癌症,但无法用染色体的获得或丢失来解释。
该团队决定将他们之前的测试(能够检查 DNA 中的 350,000 个重复位置)与公正的机器学习方法结合起来。
Douville 及其同事收集了 3,105 名实体癌症患者和 2,073 名非实体癌症患者的样本。该研究涵盖 11 种癌症类型和 7,615 份血液样本。这些重复被用作重复,以观察模型的效果如何。他们的特异性达到了 98.9%,这意味着他们可以最大限度地减少假阳性检测结果。“这在筛查无症状患者时至关重要,这样人们就不会被错误地告知他们患有癌症,”杜维尔说。
作者在论文中写道,在一个独立的验证队列中,将 Alu 元素添加到机器学习模型中,发现了 8 种现有生物标志物和该小组之前的测试漏掉的 41% 的癌症病例,“比非整倍体或蛋白质做出了更大的贡献”。 ” 对癌症检测贡献最大的重复 DNA 类型是最大的 Alu 元素亚家族,称为 AluS;癌症患者的血浆中这种物质的含量比平时要少。
Douville 说,尽管 Alu 元素占人类和其他灵长类动物 DNA 的 11%,但长期以来一直被认为很难用作生物标记。“它们很小而且重复——技术上很困难。但这项研究表明,计算血浆中 DNA 的重复长度(来自全身器官的各种 DNA 片段)具有成本效益,并且可以增强早期癌症检测,”Douville 说。他们设想将基于 Alu 的癌症检测作为临床医生可用的其他癌症检测工具包的补充。下一步是优先考虑哪些生物标志物似乎最有前途并将它们聚合在一起。
研究合著者包括 Kamel Lahouel、Albert Kuo、Haley Grant、Bracha Erlanger Avigdor、Samuel D. Curtis、Mahmoud Summers、Joshua D. Cohen、Yuxuan Wang、Austin Mattox、Jonathan Dudley、Lisa Dobbyn、Maria Popoli、Janine Ptak、Nadine Nehme、娜塔莉·西利曼、切丽·布莱尔、凯瑟琳·罗曼斯、克里斯托弗·托本、詹妮弗·吉齐、迈克尔·戈金斯、施益民、安妮·玛丽·列侬、拉尔夫·H·赫鲁班、Chetan Bettegowda、肯尼思·W·金兹勒、尼古拉斯·帕帕多普洛斯、伯特·沃格尔斯坦和克里斯蒂安·托马塞蒂约翰霍普金斯大学医学院和希望之城。
其他作者来自匹兹堡大学医学系和流行病学系;纽约大学朗格尼分校外科系;以及越南(范玉石医学院和西贡精准医学研究中心)和澳大利亚(沃尔特和伊丽莎霍尔医学研究所、墨尔本大学、悉尼科技大学和新南威尔士大学)。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。